
不確実性の高い事象を予測する際、単一の機械学習アルゴリズムに依存すると、データに潜む特定のノイズに過剰適合(過学習)してしまうリスクが伴います。
当プロジェクト「AI-Brains」では、現在稼働中の実証実験(PoC)モデル、および開発中のより複雑な予測システムにおいて、特性の異なる複数のAIを組み合わせた「多層アンサンブル学習(スタッキング)」を採用しています。本稿では、その技術的なアーキテクチャと予測の根拠について解説します。
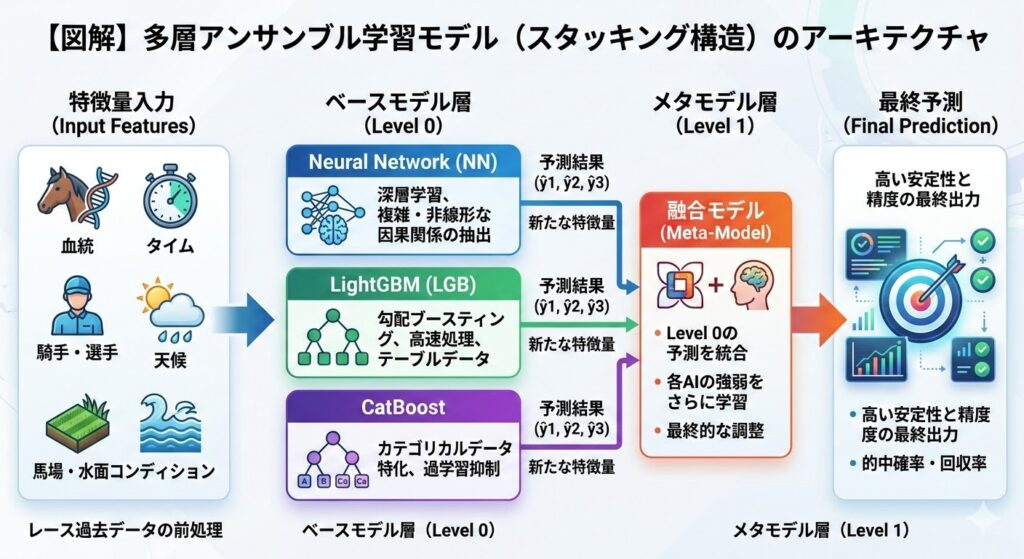
1. なぜアンサンブル学習(スタッキング)なのか?
スタッキング(Stacking)とは、複数のベースモデル(Level 0)が算出した予測結果を、さらに別のメタモデル(Level 1)に入力し、最終的な予測値を導き出す手法です。
これにより、各アルゴリズムの弱点を相互に補完し、未知のデータに対する汎化性能を飛躍的に向上させることができます。
当システムの予測ロジックは、以下のような関数として定式化されます。
$$\hat{y} = f_{meta}(M_{NN}(X), M_{LGB}(X), M_{Cat}(X))$$
ここで、$X$は入力特徴量群、$\hat{y}$は最終的な予測値(勝率や期待値など)を表します。
2. Level 0:3つの強力なベースモデル
システムの中核となるベースモデルには、データの捉え方が根本的に異なる3つのアルゴリズムを採用しています。
- Neural Network (NN:ニューラルネットワーク)深層学習モデル。データ間の複雑で非線形な因果関係を抽出する能力に長けています。当システムでは、多層パーセプトロンを用いて、人間では見落としがちな微細な特徴量の組み合わせを学習させます。
- LightGBM (LGB)マイクロソフト社が開発した勾配ブースティング決定木フレームワーク。テーブルデータ(表形式データ)の処理において世界トップクラスの計算速度と予測精度を誇ります。ヒストグラムベースのアルゴリズムにより、膨大な過去データを高速かつ効率的に学習します。
- CatBoostYandex社が開発した、カテゴリカルデータ(文字列などの数値化しにくいデータ)の処理に特化したブースティングモデル。公営競技のデータに含まれる「天候」「レース場名」「選手・騎手の固有データ」などを、ターゲット統計量(Target Encoding)を用いて直接的に高精度で処理し、Target Leakage(情報漏洩)による過学習を強力に抑制します。
3. Level 1:メタモデルによる最適化
上記3つのモデルが出力した予測値(確率やスコア)は、メタモデルへと渡されます。
メタモデルは「どのような状況下でどのAI(NN、LGB、CatBoost)の予測を信頼すべきか」を学習します。たとえば、「特定の条件下ではCatBoostの出力に重み付けをする」「全体的に荒れる展開のときはNNの出力を重視する」といった微調整を自動で行い、最終的な予測値 $\hat{y}$ を決定します。
4. 今後の展望:より複雑な環境への適応
現在公開中のボートレース予測(6つの変数)は、このスタッキングモデルの基礎的な挙動を確認するための第一歩です。
当プロジェクトが最終的な本丸として開発を進めているのは、これらの技術を基盤とした「競馬予測システム」です。血統や馬場状態、多頭数による複雑な展開など、極めて多次元的なパラメータが交差する環境下において、この「NN×LGB×CatBoost」のアーキテクチャが真価を発揮すると考えています。
当サイトでは、今後もデータサイエンスの視点から、アルゴリズムの調整や特徴量エンジニアリングの過程を発信してまいります。

コメント